
Application Note for QuNect ODBC for QuickBase
Schema Caching to Reduce Integration Reads
This is a new feature of the 2024 release of QuNect ODBC for QuickBase. The setting is called Schema Cache DBID.
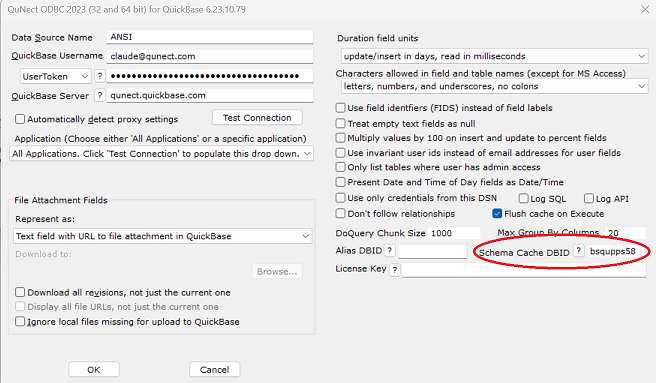
It can be left blank if no schema caching is desired. If you want to take advantage of schema caching then you enter the DBID of a table that has two columns called Schema and DBID. The key field of the table must be the column labeled DBID. The DBID column must be a text field and the Schema column must be a file attachment field. When this feature was first introduced in the 2023 product the product required that the Schema column be a text field. This has changed and the 2024 product and beyond requires a file attachment field for the Schema column. This was changed because many customers had tables where the schema exceeded the one megabyte limit of Quickbase text fields.
To keep your schema cache from getting stale you might want to set up a Quickbase pipeline to delete all records in your schema cache table every day or week. Of course if you make a change to a Quickbase table, QuNect ODBC for QuickBase will not become aware of the change until you delete the corresponding record in the schema cache table and drop any open ODBC connections. You can ensure that your ODBC connections are dropped by exiting out of the application that is using QuNect ODBC for QuickBase or restarting the service that uses QuNect ODBC for QuickBase. For example SQL Server is a service that can use QuNect ODBC for QuickBase through it linked server feature. You can also execute a
SELECT * FROM dbid~flush
statement where "dbid" is replaced with the DBID of the table whose schema has changed. Executing this SELECT statement will delete the corresponding record in the schema cache table and erase the in memory schema information.
Remember if you are using a user token for authentication, this table must be contained within an application that is associated with your user token.
Enabling this feature will reduce the number of API_GetSchema calls (each one is counted as an integration read). Each ODBC connection will incur one API_GetSchema, and one API_Doquery call instead of multiple API_GetSchema calls. If you only access two different tables or less per ODBC connection then schema caching will not benefit you. However keep in mind that even if you access only one table directly, if it is related to other parent tables then the schemas of those parent tables will need to be accessed including the parents of parents and so on. So in the case of applications with many related tables, schema caching can help performance and reduce API_GetSchema integration reads.